


Meta AI
Last week, Meta announced an AI-powered audio compression method called “EnCodec” that can reportedly compress audio 10 times smaller than the MP3 format at 64kbps with no loss in quality. Meta says this technique could dramatically improve the sound quality of speech on low-bandwidth connections, such as phone calls in areas with spotty service. The technique also works for music.
Meta debuted the technology on October 25 in a paper titled “High Fidelity Neural Audio Compression,” authored by Meta AI researchers Alexandre Défossez, Jade Copet, Gabriel Synnaeve, and Yossi Adi. Meta also summarized the research on its blog devoted to EnCodec.

Meta AI
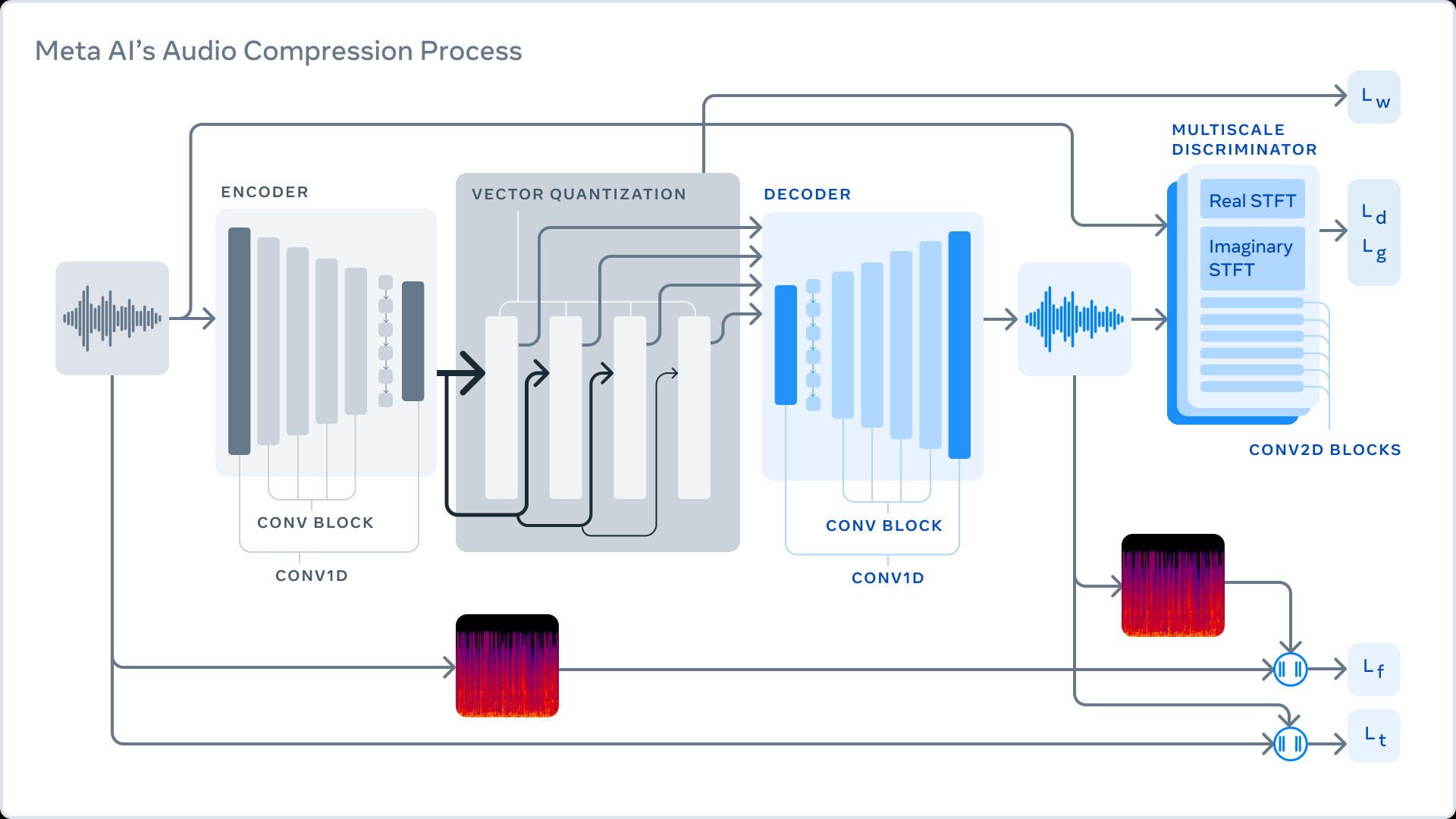
Meta describes its method as a three-part system trained to compress audio to a desired target size. First, the encoder transforms uncompressed data into a lower frame rate “latent space” representation. The “quantizer” then compresses the representation to the target size while keeping track of the most important information that will later be used to rebuild the original signal. (This compressed signal is what gets sent through a network or saved to disk.) Finally, the decoder turns the compressed data back into audio in real time using a neural network on a single CPU.
Meta AI
Meta’s use of discriminators proves key to creating a method for compressing the audio as much as possible without losing key elements of a signal that make it distinctive and recognizable:
“The key to lossy compression is to identify changes that will not be perceivable by humans, as perfect reconstruction is impossible at low bit rates. To do so, we use discriminators to improve the perceptual quality of the generated samples. This creates a cat-and-mouse game where the discriminator’s job is to differentiate between real samples and reconstructed samples. The compression model attempts to generate samples to fool the discriminators by pushing the reconstructed samples to be more perceptually similar to the original samples.”
It’s worth noting that using a neural network for audio compression and decompression is far from new—especially for speech compression—but Meta’s researchers claim they are the first group to apply the technology to 48 kHz stereo audio (slightly better than CD’s 44.1 kHz sampling rate), which is typical for music files distributed on the Internet.
As for applications, Meta says this AI-powered “hypercompression of audio” could support “faster, better-quality calls” in bad network conditions. And, of course, being Meta, the researchers also mention EnCodec’s metaverse implications, saying the technology could eventually deliver “rich metaverse experiences without requiring major bandwidth improvements.”
Beyond that, maybe we’ll also get really small music audio files out of it someday. For now, Meta’s new tech remains in the research phase, but it points toward a future where high-quality audio can use less bandwidth, which would be great news for mobile broadband providers with overburdened networks from streaming media.






{kind=link}